통계 테이블로 조회시간 줄이기
개요
현재 데이터베이스 서버는 NCP Micro Server(vcpu 1개, RAM 1GB)를 쓰고 있다. 하루 2000~3000건씩 꾸준히 배치를 돌려온 결과 어느덧 데이터가 100만건에 달하게 됐다. 그에따라 점점 쿼리가 느려지기 시작했는데 10만건부터 몇십초가 넘게 걸리더니 이젠 오래 걸리는 건 5분가까이나 걸리게 되었다.. 프론트를 아직 안만들어서 유기해놓고 있었는데 가끔 테스트해볼때도 너무 불편해서 고치기로 마음먹었다.
통계 테이블
이전 프로젝트의 통계 테이블
해결 방법으로는 여러가지가 있겠지만 통계 테이블을 따로 만들기로 했다. 예전에 했던 멘토링에서 이미 얘기가 나오기도 했고, 예전 프로젝트때도 리뷰수 같은 것들을 따로 만들어 조회때마다 쿼리를 날리지 않도록 해봤기 때문이다. 보통 느린 쿼리를 해결하려는 노력이 먼저겠지만 여러 테이블을 조인하는 것도 아니고 한 테이블에서 AVG(평균값)같은 연산을 하는 것이기 때문에 쿼리는 변경의 여지가 없었다.
이전 프로젝트는 리뷰가 하나 만들어질때마다 리뷰수를 한 개씩 늘렸다. 리뷰를 생성하는 로직과 리뷰수를 증가시키는 로직을 분리시키기 위해 AOP를 사용한다거나 동시에 리뷰수를 증가시킬때 값이 누락될 것을 예상해 애플리케이션 단에서 비관적 락을 거는 것을 고려하기도 했다.
현재 통계 테이블
이번 프로젝트는 대신 일정시간마다 배치를 돌려 평균값을 데이터베이스에 저장한다. 데이터가 늘어날때마다 느린 쿼리를 돌리는 건 곤란하기 때문이다. avg(평균값)과 count(데이터 수)를 두어 데이터가 들어올때마다
1
( (avg * count) + 새로 들어온 데이터 값 ) / 총 데이터 수
를 계산하여 값을 저장하는 방법도 있었는데 [소수점이 몇 개까지 되는지, 연산할때마다 손실값은 없는지] 따지는 과정이 배치를 돌리는 것보다 어려워서 배치를 돌리기로 마음먹었다. 그렇다면 배치를 돌릴 때 Spring Batch를 이용해 Jenkins에서 돌릴까? 아니면 @Scheduled를 이용해 cron값을 통해 돌릴까?
상황에 맞는 배치 전략
일단 Jenkins 서버가 이미 있긴 하다. 하지만 이 서버는 하루 2000~3000건을 받아오는데에도 버거워했다. 배치지만 사실상 24시간 돌아가는 느낌이기 때문이다. 파일, 네트워크 I/O가 계속 돌아가서 심지어 Jenkins 사이트를 못 들어갈 때도 있다. 이것도 어찌 해보려했는데 많은 것을 해보다가 vcpu 1개의 한계라고 일단 결론지었다. 모니터링을 해보려고 prometheus exporter를 깔았는데 이것도 제때 응답하지 못했다.

나중에 다시 봐야되는데..
어쨋든 이러한 이유 때문에 API 서버에서 돌려야 한다. 통계 자료를 추출하는 Repository와 Service는 이미 만들어져 있는 상태에서, 통계 테이블에 넣어주는 부분만 추가하면 돼서 @Scheduled를 이용해 API 서버에서 배치를 돌리기로 했다.
구현
이제 고려해야될 것은 한 가지인데.. 저장은 할건데 어떻게 저장하냐는 것이었다. 각각 API 마다 데이터 형식이 조금씩 달랐다. Double 값이 1개만 나오는 것, Double 값이 여러개 나오는 것, id·count가 리스트 형식으로 나오는 것 등등… 이 문제는 프론트에서 어떻게 나타내냐로 이어지는데 각각의 API마다 템플릿을 만들어야한다. 아무튼 그래서 저장방식은 간단하게 ObjectMapper로 Json 맵핑하기로 했다. 그래서 최종적으로
- N분마다 @Scheduled로 배치돌리기
- 통계 쿼리를 날려서 값 받아오기
- 받은 값을 Json으로 변환해 통계 테이블에 저장하기
- API가 날아오면 통계 테이블에서 Json 가져온 것을 재변환해 반환
이렇게 되겠다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Scheduled(cron = "* */5 * * * *") // 5분마다 실행
public void avgPingsUsed() throws JsonProcessingException {
PingDto avgPingUsed = matchExtraRepository.avgPingUsed(); // 통계값 받아오기
String avgPingUsedJson = objectMapper.writeValueAsString(avgPingUsed); // Json으로 변환
Optional<Statistics> findByName = statisticsRepository.findByName("avgPingUsed"); // 동일한 이름의 통계가 있는지 확인
if(findByName.isEmpty()) { // 없으면 저장
Statistics statistics = Statistics.builder()
.name("avgPingUsed")
.contents(avgPingUsedJson)
.build();
statisticsRepository.save(statistics);
}
else { // 있으면 통계지표 바꾸기
findByName.get().changeContents(avgPingUsedJson);
}
}
↑ 예제 코드
결과
Postman
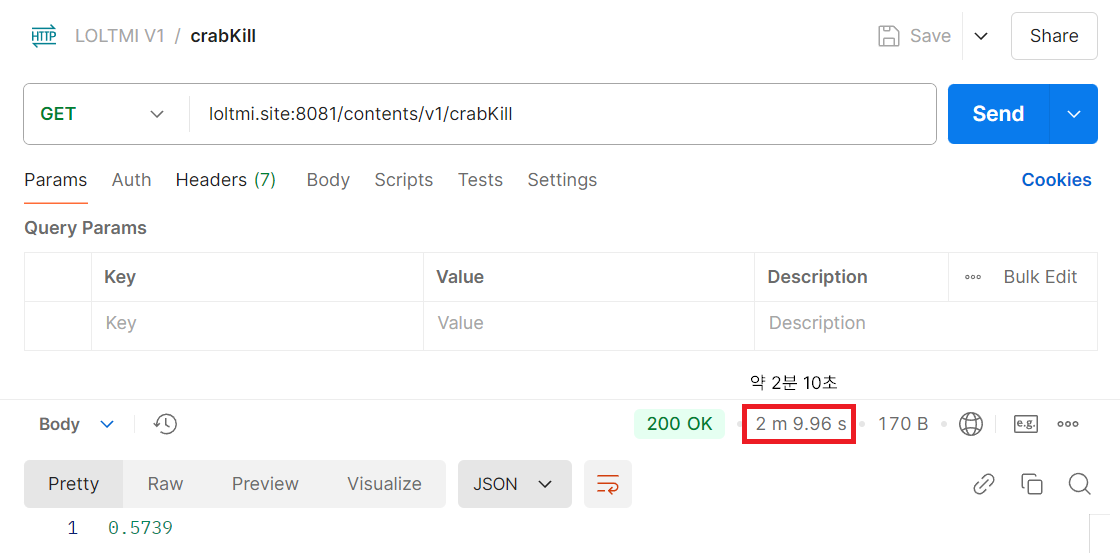
↑ API V1(느린 쿼리 버전) - 129960ms
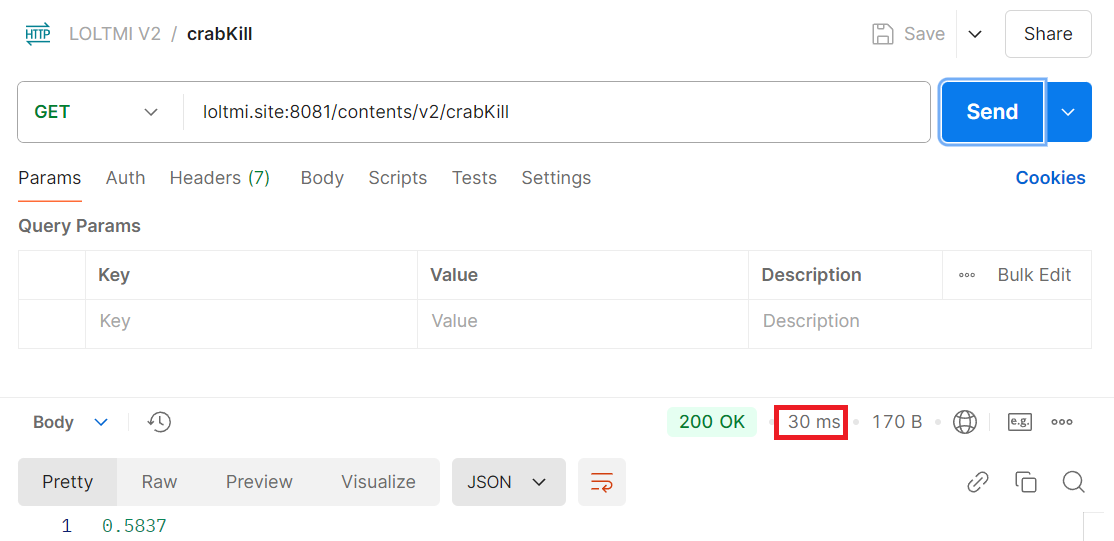
↑ API V2(통계 테이블 버전) - 30ms(아마 캐시일수도 있다. 보통 60ms 정도로 나왔다)
비교를 할 수 없을 정도의 차이가 난다.
Ngrinder
더 그럴듯한 지표를 보여주기 위해 ngrinder를 세팅해 1시간 동안 여러번 요청해서 평균 응답 시간이 얼마나 나오나 보려고 했다. 하지만 “Too low TPS” 오류가 뜨면서 멈췄다. 어느 ngrinder forum을 보니 1분동안 TPS가 0.001 미만으로 나오면 스크립트가 잘못된 것으로 판단해 멈춰버린다고 한다. 이건 설정으로 건드릴 수 없는 부분이라 다른 테스트 도구를 고려해봐야겠다.
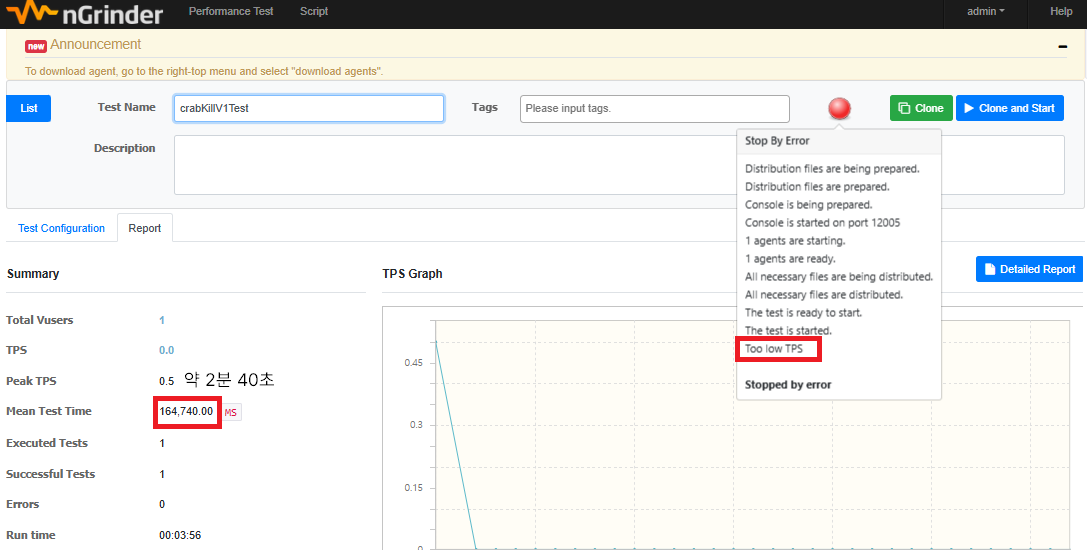
↑ API V1(느린 쿼리 버전) - 164740ms
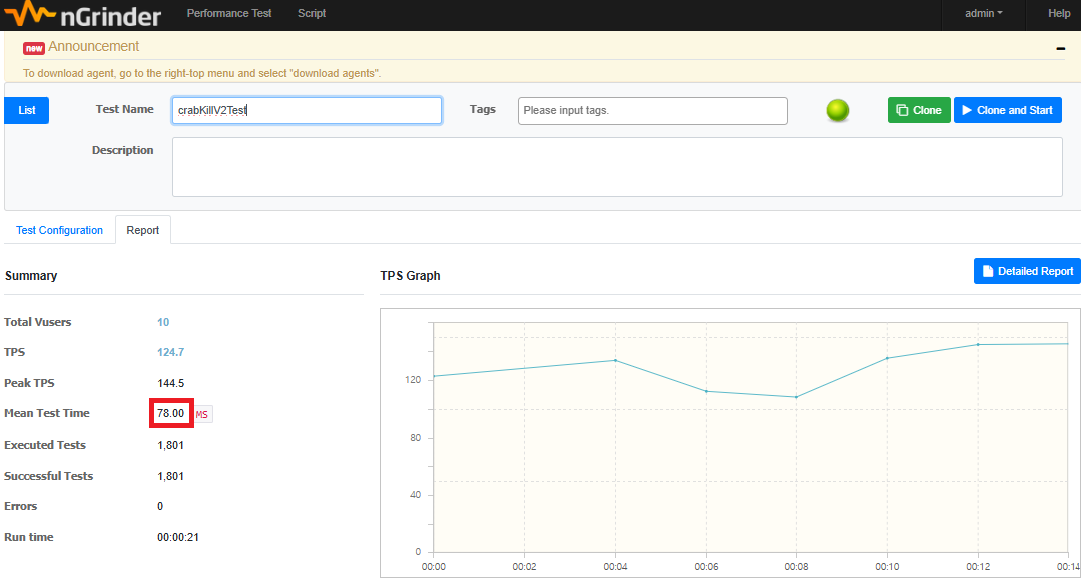
↑ API V2(통계 테이블 버전) - 78ms
추가로 해볼만한 것
Redis
여기서는 사용하던 MySQL에 Statistics 테이블을 추가해서 사용했다. 간단하게 id, name, content 컬럼만 두어서 name에 API 이름, content의 Json을 넣었다. 지금이야 당연히 이렇게 사용하는데 걸림돌이 없지만, 극한의 성능을 추구하자면 In-memory 데이터베이스인 Redis를 써도될 것 같다. 하지만 지금의 RDB에서도 60ms 정도의 응답시간을 가져서 고려만 해보면 될 것 같다. 예전부터 기술력을 늘리기 위해 이런 것들을 상황을 가정해놓고 써보려고 했는데, 실감이 안나는 곳에는 손이 가지 않아 결국 해보더라도 진짜 깔아서 써보기만 하는거지 퀄리티가 낮아서 기억에 잘 남지 않았다. 혹시라도 나중에 해볼 수도 있으니 생각만 해두어야겠다.
mysql event scheduler + procedure
애플리케이션 단에서 스케쥴러를 사용하지 않고 데이터베이스에서 스케쥴러를 사용하는 방법이다. 간단하게 순서를 보면
- 통계를 만드는 프로시저를 만든다
- 이벤트 스케쥴러를 “ON”으로 만든다
- 이벤트를 만들고 시간을 설정 후 “DO” 항목에 만든 프로시저를 넣는다
이렇게 된다. 특정 시간에 실행하고 자동으로 지워지는 기능도 지원한다고 한다.
trigger + procedure
이전 프로젝트에서 AOP로 만들었던 것을 DB에서 구현하는 것이다. 이벤트 스케쥴러와 비슷하게 트리거를 만들고 프로시저를 호출해 통계값을 가져온 후 통계 테이블에 삽입하면 된다.실시간 수집 데이터를 관리하는, 통계 테이블 관리하기에 자세히 나와있어서 나중에 시도해볼 상황이 생기면 다시 찾아볼 것 같다.
다만 내 프로젝트에는 통계값을 가져오는 조회시간이 길기 때문에 사용하지 못한다. 이 블로그는 실시간성이 필요하기 때문에 사용했지만 나는 5분마다 보여줘도 상관없는 값이기 때문에 상관없다. 만약 내 프로젝트에 실시간으로 사용하려면 데이터베이스를 복제해서 통계용 데이터베이스를 사용해봐야하지 않을까 싶다. 이것도 해본다면 Master/Slave의 동기화 등 아주 좋은 공부가 될 것도 같다. 하던게 끝나면 이것도 해봐야겠다.