요기요 앱 주소 체제 바꾸기
「요기요」 앱을 클론코딩하는 프로젝트를 진행하였다. 보는대로 따라만드는 거라 처음엔 큰 어려움은 없었다. 점주 입장에서 음식점을 등록하고 고객 입장에서 음식점을 조회하는, 게시판의 확장 버전 정도?
그렇게 설계와 구현이 끝나가는듯 싶더니 여러가지 문제점이 발생했다. 그 중 대표적인 것이 음식점 리스트를 조회하는 페이지가 눈에 띄게 느려진 것이다. 처음엔 어떻게든 바꾸고 바꿔서 온몸 비틀기하다가 결국에는 한계를 보고 설계를 다시 생각하는 상황까지 왔다. 처음 시작부터 해결하기까지의 과정을 살펴보자.
1. Shop(음식점) 테이블 설계
| 기능 | 내용 |
| 정렬 | 주문 많은 순, 리뷰 많은 순, 별점 높은 순, 거리순 |
| 필터링 | 카테고리, 최소 주문 금액, 배달금액 |
- ERD
- 조회 쿼리
1
2
3
4
5
6
7
8
9
10
select *, st_distance_sphere(point(curLongitude, curLatitude), point(s.longitude, s.atitude)) as distance
from shop s
join category c on s.category_id = c.id // category 테이블과 조인
where (
c.name = ??? // 카테고리
and s.least_order_price < ??? // 최소주문금액
and s.min_delivery_price < ??? // 최소배달금액
and distance < 10000 // 반경 10km 이내 상점만 조회
)
order by SortOption(orderNum, reviewNum, totalScore, distance)
고려사항
- 한 가게에 category가 여러개일수도 있기 때문에 category 테이블과 category:shop 테이블을 만들었다
- order과 review는 각각 테이블이 있고 FK로 shop_id를 가지고 있는 ManyToOne 연관관계이다. shop_id를 기준으로 조인하고 count() 쿼리로 orderNum과 reviewNum을 가져올 수 있는데 그렇게 하면 두 가지 문제점이 있다
- 성능이 안좋다
- order 테이블과 review 테이블도 각각이 로우가 많기 때문에 조회를 할때마다 count를 날리는 것은 안해봐도 느릴 것 같았다. - 테이블이 뻥튀기될 수 있다
- 보통 쿼리 하나에 해결하려고 모두 조인해놓고 시작할 때가 많은데, 이미 [shop 테이블:category 테이블] 조인을 했기 때문에 [shop 테이블:order 테이블]도 같이 조인해버리면 (category 개수 * order 개수)개의 행이 나와버린다. 이것을 피하는 방법은 from절에서 count()를 먼저 실행하기, 애플리케이션에서 두번이상 쿼리작업하는 등이 있다.
여러가지를 고려해보다가 shop 테이블에 orderNum과 reviewNum을 만들고 order과 review가 생성될 때마다 +1 해주도록 바꿨다. 제대로 만드려면 단일 책임 원칙을 따라 advice를 만들어 createOrder, createReview와 별개로 orderNum과 reviewNum을 +1하는 로직을 만들어야 됐을 것 같은데 귀찮아서 createXXX에 다 때려넣었다. 저스틴 비버문제를 참고했다.
- 성능이 안좋다
- 그냥은 st_distance_sphere 함수를 쓸 수 없다. JPA에서 기본으로 제공하는 MariaDBDialect에는 이 함수를 제공하지 않기 때문이다. 그래서 따로 MariaDBDialectConfig를 클래스로 만들고 yaml파일에 등록해줬다.
- 최소주문금액과 최소배달금액
일단 기능이 되는지 보는 것이어서 상대적으로 세세한 부분인 최소주문금액과 배달금액은 컬럼 하나로 퉁치고 넘어갔었다. 원래대로라면 shop 테이블에 있는 것이 아닌 shop_id를 FK로 가진 테이블로 따로 독립이 되어야한다. 주문금액별로 배달금액이 여러개가 나오기 때문이다.
ex) 개선 후 테이블
테이블을 만들고 조인에 추가하는 건 그렇다치고 거리를 고려하지 못한다는게 더 큰 문제였다. 똑같은 주문금액이어도 1km와 3km를 배달할때 배달비가 차이가 나야할텐데 그런 것까지는 고려하려면 어떻게 해야할까 하다가 머리가 꼬여서 일단 넘겼다.(거리까지 하면 1km이내일 때 최소주문금액이 N원이면 배달금액은 N원... 이런식으로 해야하는데 테이블이 너무 세세해져서? 일단은 넘어갔다)주문금액 배달금액 shop_id 1 50,000원 이상 주문시 1,000원 1 2 30,000원 이상 주문시 3,000원 1 3 12,000원 이상 주문시 4,000원 1
2. 데이터가 쌓여가면서 생기는 문제
더미 데이터가 30만건을 넘기기 시작했을 때의 일인가…? 점점.. 느려진다. 어떤 정렬을 하던 필터링을 하던 5초 정도나 걸려서야 조회가 됐다.
어디서 문제가 일어나는지는 뻔했다. 데이터베이스였다. 애플리케이션은 DTO로 감싸서 보내주는 것만 수행했고 데이터베이스는 Amazon RDS Freetier(MariaDB)를 사용하기 때문에 메모리가 1GB밖에 안돼서 사실 언제 터지나 궁금하긴했다.
원인으로 생각되는 것은 페이지네이션, st_distance_sphere 함수 등이었다. 쿼리를 날릴 때 주위의 상점만 조회하기 위해 모든 로우에 대해 st_distance_sphere를 실행하기 때문에 시간이 오래걸릴 것이다. 거기다 페이지네이션으로 limit, offset을 받아 간단히 구현했기 때문에 뒤로 갈수록 느려지는 느낌도 있었다.
애플리케이션에서 거리계산하는 부분을 수행해볼까도 생각해봤는데 어차피 애플리케이션도 똑같이 Amazon EC2 Freetier라 별다를게 없을 것 같아 패스하고(지금와서야 생각해보면 그래도 해볼 걸 그랬다. 다음에 비슷한 상황이 오면 해봐야겠다), 쿼리를 어떻게 건드려보기로 했다.
3. 쿼리튜닝
먼저 문제의 큰 원인이 st_distance_sphere 함수라고 생각했기 때문에 최대한 이 함수를 덜 쓰는 방향으로 생각했다. 처음부터 모든 거리를 계산하지 말고 일단 필터링으로 거를건 먼저 거르고, 주변 10km내에 있는 상점을 가져오기로 했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// QueryDSL
// (1) subquery로 필터링된 shop_id 먼저 받기
OrderSpecifier<?> orderSpecifier = getOrderSpecifier(request.getSortOption());
List<Long> filteredShopId = jpaQueryFactory
.select(shop.id)
.from(shop)
.where(
categoryNameEq(request.getCategory()),
deliveryPriceLt(request.getDeliveryPrice()),
leastOrderPriceLt(request.getLeastOrderPrice())
)
.orderBy(orderSpecifier)
.limit(request.getLimit())
.offset(request.getOffset())
.fetch();
// (2) 필터링된 filteredShopId에서 거리 계산하고, 거리순 정렬이면 거리순 정렬 추가로 해주기
return jpaQueryFactory
.select(Projections.fields(ShopScrollResponse.class,
…
getShopDistance(request.getLatitude(), request.getLongitude()).as("distance"),
…
))
.from(shop)
.where(shop.id.in(filteredShopId))
.orderBy(orderSpecifier);
.fetch();
생략된 부분이 많아서 의사코드로 생각하면 좋을 것 같다. 핵심은 쿼리를 두번에 걸쳐서 실행했다는 것이다. 1)필터링한 쿼리를 먼저 받고, 2)필터링된 항목에 대해서만 거리계산을 한다.
거기다가 추가로 신경쓰였던 페이지네이션도 무한스크롤로 바꿔줬다. 무한스크롤과 querydsl을 사용하는데에는 이동욱님 블로그를 참고하였다. 최종본을 SQL로 보여주면(위에껀 애플리케이션에서 두번에 걸쳐서 실행했다는 것을 보여주기 위해 querydsl을 보여줬다)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
-- ex) 주문 많은 순 정렬
-- (2)
SELECT *, st_distance_sphere(point(curLongitude, curLatitude), point(s.longitude, s.atitude)) as distance
FROM shop
WHERE shop.shop_id IN (
--(1)
SELECT * from
(
SELECT shop.shop_id
FROM shop
JOIN category_shop ON category_shop.shop_id=shop.shop_id
JOIN category ON category_shop.category_id=category.category_id
WHERE category.name='치킨'
AND shop.min_delivery_price<=3000
AND shop.min_order_price<=10000
AND ( (shop.order_num=467 and shop.shop_id<2000000) OR shop.order_num<467 )
ORDER BY shop.order_num DESC
LIMIT 10
) AS tmp
) and distance < 10000
무한스크롤에 대한 설명은 넘어가고,, 쨋든 무한스크롤 했다! MainCursor(orderNum, reviewNum…), SubCursor(shop_id)를 받아서 무한스크롤의 cursor로 삼았다. xxxNum은 중복값이 있기 때문에 중복되면 shop_id로 판별하고, 값이 다르면 xxxNUM으로 판별한다는 뜻이다. 자세한 건 이 LG유플러스 기술 블로그를 참고했다. 야무지게 성능개선한다고 정렬기준이 되는 xxxNum은 인덱스까지 만들었다.
쿼리 튜닝을 하고난 다음엔 1.xxx초대로 쿼리가 빨라졌다. 은근 나름 굉장히 뿌듯했지만 얼마 안갔다. 필터링을 다빼고 조회를 하면 filteredShopId이 모든 행에 대해 나왔기 때문에 또다시 지옥의 거리계산을 하기 때문이다.
사실 이 필터링을 제외한 초기화면이 나오는 속도가 제일 중요했다. 신규 유저를 포함한 대다수의 유저들이 이 화면을 볼 것이기 때문이다. 나중에 어떻게든 하겠지하고 넘기고 일단 무한스크롤이랑 인덱스랑 querydsl이랑 이것저것 해보자라는 생각이었다. 더미 데이터를 100만건 정도로 서서히 늘리니 필터링을 제외한 조회는 한번 하는데 15초정도가 걸렸었다. 서버가 안죽고 15초동안 계산해서 준 것도 신기했다.
이제는 더이상 물러날 데가 없다…
4. 주소 구조 변경
이 난관을 헤쳐나가기 위해 가장 떠오르는 것은 스케일업이었다. 아주아주 좋은 방법이지만 공부를 위한 프로젝트이기때문에 조금 더 생각해보기로 했다. 이것저것 찾아보다가 같은 배달앱인 우아한형제들의 기술블로그에서 힌트를 얻었다.
사실 거리순으로 계산하는 것에 처음부터 의문이 있었다. 이게 거리로 돌아가는 구조가 맞을까? st_distance_sphere 함수는 범위가 원이고 초기에 테스트 할때는 위도·경도±K로 사각형의 범위를 가졌었다. 이렇게 되면 거리순으로 배달금액을 정하는 현재 구조에서는 같은 동네인데 심지어는 바로 옆집이어도 거리순때문에 배달비가 달라질 수가 있다는 것이다.
아까 말했듯 테이블에 값을 넣기도 애매해서 “거리에 따라 동적으로 배달요금이 결정되나?”, “GPS까지 연결해서 현재 교통상황에 따른 배달시간에 따라 결정되나?” 등의 여러가지 생각도 했었다. 거리계산문제를 해결하려다 보니 너무 거리라는 것에 빠져서 더 큰 그림을 못본 것 같았다.
블로그에서 행정동, 법정동 얘기가 나오는데 이걸보니 “아, 거리순으로 판단하는게 아니라 동으로 판단하고 그 기준이 되는 법정동이라는게 있구나” 라는 것을 알았다. 그치 당연히 이게 맞지 싶겠지만 안보일때는 진짜 모른다. 이래서 책읽고 강의들으면서 견문을 넒히라는 얘기를 하나싶기도 했다. 아무튼 방법을 알았으니 구조를 바꾸는데에는 생각보단 쉬웠던 것 같다.
shop_id를 FK로 가지고 법정동 정보가 있는 delivery_place 테이블과 delivery_place_id를 FK로 가지고 동마다 주문금액, 배달금액이 적힌 delivery_price_info 테이블이 탄생했다. 이걸 보기 쉬운 테이블로 표현해보자
- delivery_place 테이블(shop_id=1인 shop은 신당동, 청구동에 배달할 수 있다)
법정동 코드 배달 시간 최대배달금액 최소배달금액 최소주문금액 법정동 이름 shop_id 1 1111010100 (평균)32분 4,000원 1,000원 12,000원 신당동 1 2 1111010101 (평균)35분 4,500원 1,500원 15,000원 청구동 1 - delivery_price_info 테이블(shop_id=1인 shop이 신당동으로 배달할때 배달정보)
최소주문금액 배달금액 delivery_place_id 1 50,000원 이상 주문시 1,000원 1 2 30,000원 이상 주문시 3,000원 1 3 12,000원 이상 주문시 4,000원 1
※ 예를 들어 현재 위치에서 음식점 리스트를 조회해보면
- 내 위치가 GPS를 통해 (위도, 경도)로 나타난다
- 카카오맵 API를 통해 (위도, 경도) -> 법정동코드로 바뀐다
- 법정동코드와 일치하는 delivery_place 테이블의 행들을 가져온다(해당 지역에 배달할 수 있는 음식점 리스트가 나온다)
- delivery_place 테이블과 shop 테이블을 조인하면 1:1로 나온다(하나의 상점은 한 지역에 두 개이상 등록할 수 없기 때문에)
- 필터링이 걸리면 delivery_place 테이블의 {xxx_delivery_price, min_order_price}, shop 테이블의 {xxxNum...}으로 판단한다
5. 결과
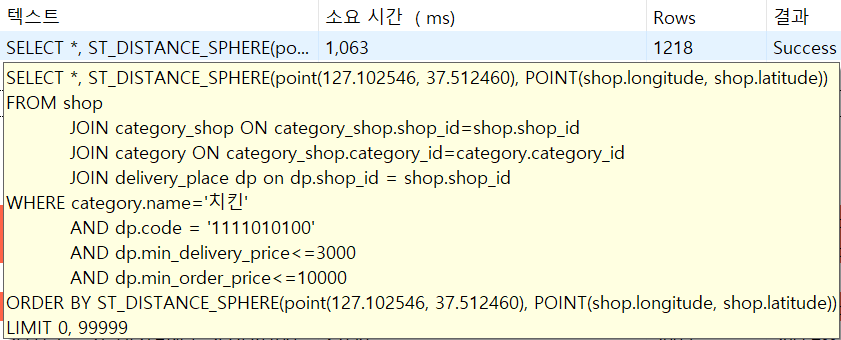
이제 필터링을 하지 않은 쿼리도 delivery_place 테이블과 조인하여 주변 상점만 가져오면 되기 때문에 오히려 필터링한 쿼리보다 더 빠를 것이다. 5493ms → 1063ms 약 5.5배의 성능 개선이 이루어졌는데 사실 5493ms가 나온 쿼리는 약 30만건의 데이터이고 1063ms가 나온 쿼리는 약 100만건의 데이터이기 때문에 같은 수의 데이터를 기준으로 한다면 약 15배는 될 것이다.
100만건일때 전자의 속도를 캡쳐해놓지 않은게 아쉽다(약간 다른 길로 새는 말이지만 이렇게 예전 데이터를 가지고 있어야 할 때는 어떡하지? 라는 물음에 flyway라는 툴로 버전관리를 하고, 데이터는 DB 툴로 export하거나 dump 파일로 저장하는 등으로 해결할 수 있다고 한다).
6. 느낀점
- 문제 정의를 잘 못했다. 쿼리튜닝 부분에서 필터링한 리스트 조회만 개선이 됐다. 말했듯이 기술에 대한 공부목적도 있긴했지만 사실 할게 많아서 헷갈리다가 이렇게 된 것이기도 했다. “나중에 어떻게든 되겠지” 했지만 모든 행에 거리계산을 하는 건 해결이 안됐다. 만약 시간이 없는 상태였으면 시간만 날린 실패한 개선이었다
- 하나가 바뀔때마다 테스트하고 지표를 기록하지 않은 것이 후회된다. 한 가지를 바꾼 후에 테스트를 해서 지표를 보고 전후를 비교하고 다시 한 가지를 테스트하고 이런식으로 했어야됐는데 한번에 여러가지를 바꿔버리기도 했고 바꾸는데에 성공한 것도 지표로 저장해놓지 않은 것도 있어 이 글을 쓸때도 증거로 제시하지 못해 설득력이 떨어지는 부분도 분명히 있다. 그때 당시에는 인식하고 있음에도 번거로운 작업이기도 하고 익숙하지도 않은 작업이라 안했는데 습관이 되도록 노력해봐야겠다(지금 사진으로 남아있는 건 다시 해본게 많다. 다시 해보는 것도 큰 도움이 되지만 처음 할때도 기록해놓고 다시 하고 기록해본 후 비교해보는 것이 베스트인 것 같다)
- 문제 해결을 어떻게 할지를 모르겠는 상황이 많다. 경험이 많다면 “이것의 원인은 이 단계에서 어떤 부분때문에 일어났다”를 알텐데 처음엔 모르니까 여기가 문제겠거니 하고 가정해보는 수밖에 없었다. 그리고 이 문제가 진짜 여기서 일어났는지 테스트를 하는 것도 쉽지 않다. 이번 계기로 Jmeter 같은 것도 써보고 브라우저나 포스트맨에서 몇 초만에 응답됐나도 보고 하면서 하나씩 알아갔지만 누구나 보고 납득할 정도로 설득력있게 문제를 정의 하는 것은 많이 부족한 것 같다. 누가봐도 여기가 문제라는 걸 보여주고 뚜렷이 해결 방법을 제시하면 참 멋있을 것 같다.
- 기술적인 문제를 기술적으로 해결한 게 아니라 다른 방식으로 해결한 거라 특이하고 좋은 경험이었다. 다양한 블로그, 유튜브, 강의, 책 등을 평소에 읽으면 좋을 것 같다는 생각을 가지게 된다. 이번엔 운이 좋아 이리저리 뒤적거리다 기술블로그를 발견해서 해결할 수 있었고 이게 클론코딩의 장점이라고도 생각하지만 만약 레퍼런스가 없는 실상황이 오면 곤란할 수도 있겠다.