Spring Batch 성능 개선기
현재 상황
API 서버는 통계 테이블 생성을 통해 해결을 보았지만, Jenkins 서버는 여전히 들어갈 수조차 없다. 이유는 아마 Jenkins 서버 안에서 돌아가는 Spring Batch의 I/O가 많아서인 것 같다. 콘솔로 들어가 vmstat으로 모니터링 해보니 wa(I/O 동안 Cpu가 노는 정도)가 100%에 육박했다.
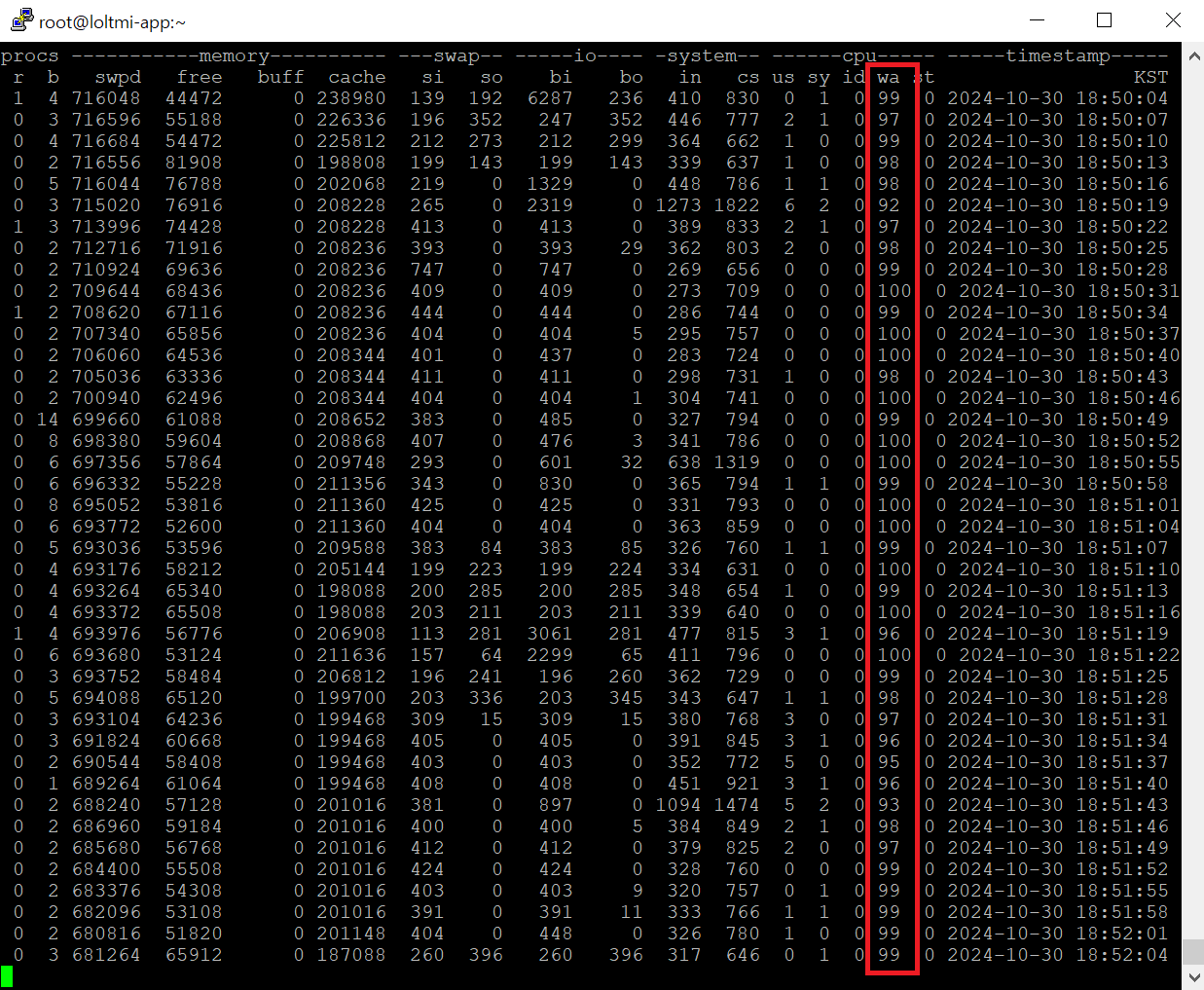
아니 아무리 Cpu가 바빠도 Jenkins 웹 사이트에 못 들어가는게 말이 안되는게 1개의 Cpu여도 Context Switching을 하며 다른 작업도 할 수 있는게 아닌가?? 하는 생각이 들지만 여전히 그.. 뭐.. 잘 모르겠다. 이에 대한 해결책으로 검색도 해보고 GPT에 물어보고 몇 가지를 생각해봤다.
- Spring Batch의 성능 개선하기 - 성능을 개선해 I/O를 줄인다면 Cpu가 다른 작업도 할 수 있을 것이다.
- Non-Blocking 전환 - 그냥 얕은 지식으로 Non-Blocking 전환을 한다면 I/O 작업 동안 다른 일을 할 수 있지 않을까 싶었는데 몇 개의 블로그를 봐본 결과 안된다고 한다
- 프로세스 우선순위 미루기 - 어차피 배치 작업이 급한 작업은 아니라 모니터링이나 웹 사이트 접속 등의 다른 프로세스에게 우선순위를 주는 건 어떨까 싶었다. 가볍게 nice 값을 변경해보라 해서 해봤는데 가볍게 안되길래 일단 패스했다.
Spring Batch 개선
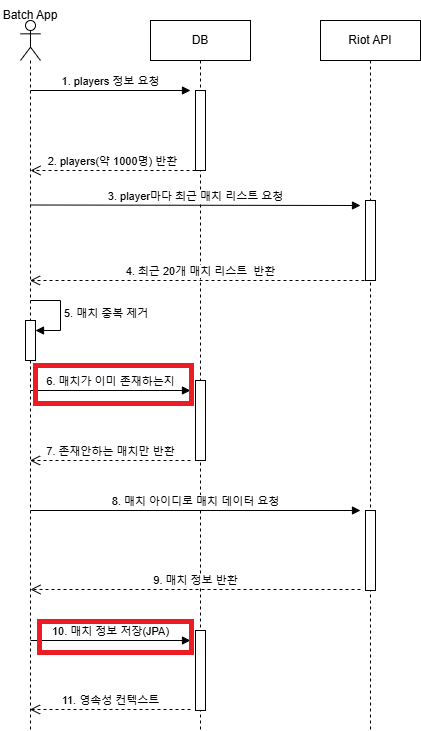
배치 애플리케이션의 시퀀스 다이어그램이다. 이 중에서 6번, 10번이 개선의 여지가 보였다.
ExistsBy
매치가 데이터베이스에 이미 존재하는지 확인하기 위해 existsById 함수를 사용했다.
1
2
3
4
5
6
7
8
9
select
case when exists(
select 1
from matches m
where m.id = :id
)
then 'true'
else 'false'
end
이 함수를 matchList에 하나씩 돌려가며 확인했다. 그런 후 false(아직 없는 매치 아이디)가 나오면 매치 데이터를 받아오는 식이었다. 이 방식은 1000개의 match가 있다면 1000번의 네트워크 I/O를 하는 것이다. 그래서 네트워크 I/O를 줄이기 위해 matchList를 한번에 보내기로 했다
1
2
3
select m.id
from Matches m
where m.id in (:MatchIds)
이렇게 하면 원래와 반대로 true(이미 있는 매치)인 MatchIds가 반한된다. 대신, forEach를 통해 원래 목록에서 remove시킨다.
1
2
List<String> alreadyExistingIds = matchRepository.getAlreadyExistsIdsByMatchList(matchIdset.stream().toList());
alreadyExistingIds.forEach(matchIdset::remove);
이렇게 되면 애플리케이션에서 반환된 아이디를 MatchIdSet에서 지우는 작업이 추가로 이루어지지만 네트워크 I/O는 1번으로 끝낼 수 있다.
Batch Insert
매치 데이터들은 JPA를 통해 저장된다. 이유는? 그땐 서버 성능이 좋은걸 써서 이렇게 해도 잘됐다. 이제는 버릴때가 됐다. JPA를 버리려는 이유는 두 가지이다.
- 영속성 컨텍스트를 유지하기 위해 추가로 리소스를 사용한다.
- batch insert가 안된다
batch insert는 여러개의 쿼리를 묶어 보내는 방식이다.
1
2
3
4
5
6
7
INSERT INTO match (name) VALUES ("match1");
INSERT INTO match (name) VALUES ("match2");
INSERT INTO match (name) VALUES ("match3");
↓
INSERT INTO match (name) VALUES ("match1"), ("match2"), ("match3");
JPA에서 batch insert가 안되는 경우는 ID 전략을 Identity로 했을 때이다. MySQL의 경우 DB에서 Auto increment가 된다. JPA는 영속성 컨텍스트를 유지하기 위해 PK가 필요한데 여러 개가 한꺼번에 insert가 되면 어떤 영속성 컨텍스트가 어떤 PK를 받을지 모르기 때문에 막아놨다고 한다. 그렇다면 saveAll()은? 내부적으로 for문을 돌려 save()를 실행해 결국 데이터 수 만큼 네트워크 I/O가 이루어진다. 그리고 나는 이 Identity 전략을 사용하고 있다.
따라서 Jdbc를 통해 bulk insert를 해야한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
String sql="INSERT INTO match (game_creation, game_duration, ... , game_version ) VALUES (?, ?, ... , ?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Match match = matches.get(i);
ps.setString(1, match.getGameCreation());
ps.setString(2, match.getGameDuration());
...
ps.setString(n, match.getGameVersion());
}
@Override
public int getBatchSize() {
return matches.size();
}
});